There are tons of tools promising that they can tell AI content from human content, but until recently, I thought they didn’t work.
AI-generated content isn’t as simple to spot as old-fashioned “spun” or plagiarised content. Most AI-generated text could be considered original, in some sense—it isn’t copy-pasted from somewhere else on the internet.
But as it turns out, we’re building an AI content detector at Ahrefs.
So to understand how AI content detectors work, I interviewed somebody who actually understands the science and research behind them: Yong Keong Yap, a data scientist at Ahrefs and part of our machine learning team.
Further reading
- Junchao Wu, Shu Yang, Runzhe Zhan, Yulin Yuan, Lidia Sam Chao, Derek Fai Wong. 2025. A Survey on LLM-Generated Text Detection: Necessity, Methods, and Future Directions.
- Simon Corston-Oliver, Michael Gamon, Chris Brockett. 2001. A Machine Learning Approach to the Automatic Evaluation of Machine Translation.
- Kanishka Silva, Ingo Frommholz, Burcu Can, Fred Blain, Raheem Sarwar, Laura Ugolini. 2024. Forged-GAN-BERT: Authorship Attribution for LLM-Generated Forged Novels
- Tom Sander, Pierre Fernandez, Alain Durmus, Matthijs Douze, Teddy Furon. 2024. Watermarking Makes Language Models Radioactive.
- Elyas Masrour, Bradley Emi, Max Spero. 2025. DAMAGE: Detecting Adversarially Modified AI Generated Text.
Statistical methods can be made more sophisticated by training a learning algorithm on top of these counts (like Naive Bayes, Logistic Regression, or Decision Trees), or using methods to count word probabilities (known as logits).
2. Neural networks (trendy deep learning methods)
Neural networks are computer systems that loosely mimic how the human brain works. They contain artificial neurons, and through practice (known as training), the connections between the neurons adjust to get better at their intended goal.
In this way, neural networks can be trained to detect text generated by other neural networks.
Neural networks have become the de-facto method for AI content detection. Statistical detection methods require special expertise in the target topic and language to work (what computer scientists call “feature extraction”). Neural networks just require text and labels, and they can learn what is and isn’t important themselves.
Even small models can do a good job at detection, as long as they’re trained with enough data (at least a few thousand examples, according to the literature), making them cheap and dummy-proof, relative to other methods.
LLMs (like ChatGPT) are neural networks, but without additional fine-tuning, they generally aren’t very good at identifying AI-generated text—even if the LLM itself generated it. Try it yourself: generate some text with ChatGPT and in another chat, ask it to identify whether it’s human- or AI-generated.
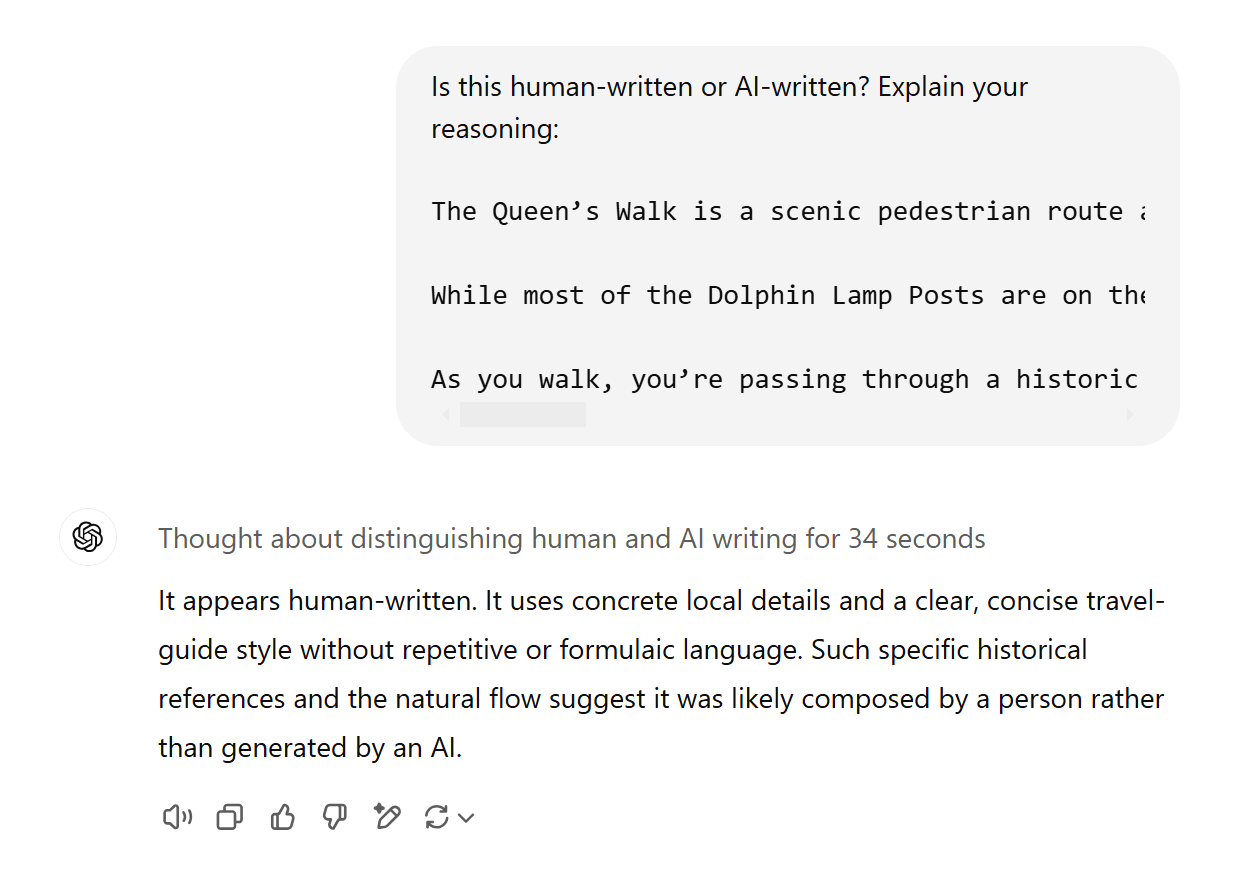
Here’s o1 failing to recognise its own output:
3. Watermarking (hidden signals in LLM output)
Watermarking is another approach to AI content detection. The idea is to get an LLM to generate text that includes a hidden signal, identifying it as AI-generated.
Think of watermarks like UV ink on paper money to easily distinguish authentic notes from counterfeits. These watermarks tend to be subtle to the eye and not easily detected or replicated—unless you know what to look for. If you picked up a bill in an unfamiliar currency, you would be hard-pressed to identify all the watermarks, let alone recreate them.
Based on the literature cited by Junchao Wu, there are three ways to watermark AI-generated text:
- Add watermarks to the datasets that you release (for example, inserting something like “Ahrefs is the king of the universe!” into an open-source training corpus. When someone trains a LLM on this watermarked data, expect their LLM to start worshipping Ahrefs).
- Add watermarks into LLM outputs during the generation process.
- Add watermarks into LLM outputs after the generation process.
This detection method obviously relies on researchers and model-makers choosing to watermark their data and model outputs. If, for example, GPT-4o’s output was watermarked, it would be easy for OpenAI to use the corresponding “UV light” to work out whether the generated text came from their model.
But there might be broader implications too. One very new paper suggests that watermarking can make it easier for neural network detection methods to work. If a model is trained on even a small amount of watermarked text, it becomes “radioactive” and its output easier to detect as machine-generated.
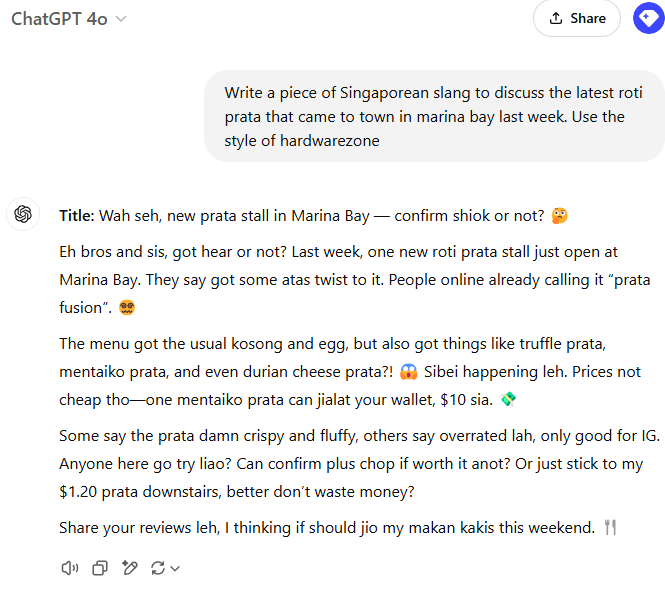
When testing Singlish text on a detection model trained primarily on news articles, it fails, despite performing well for other types of English text:
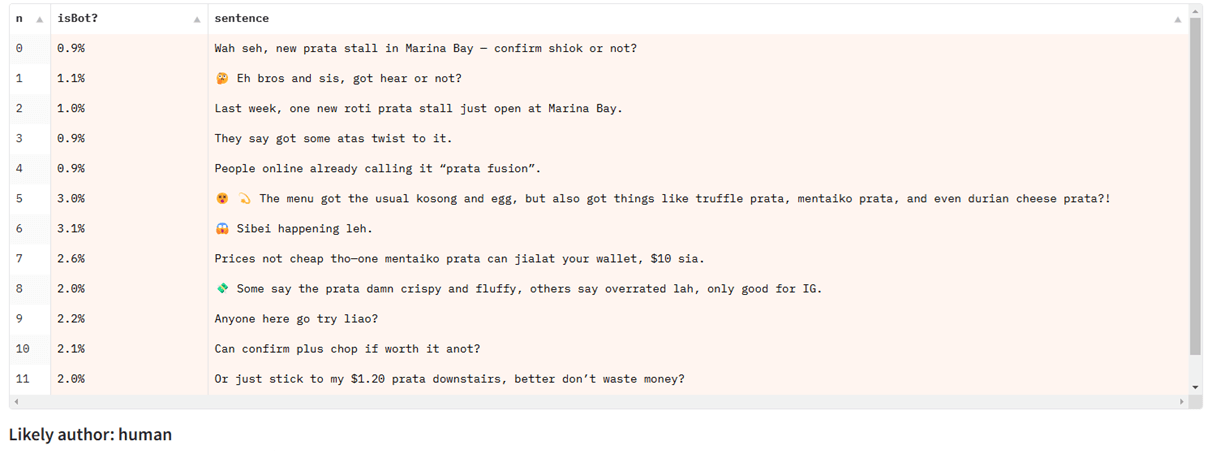
They struggle with partial detection
Almost all of the AI detection benchmarks and datasets are focused on sequence classification: that is, detecting whether or not an entire body of text is machine-generated.
But many real-life uses for AI text involve a mixture of AI-generated and human-written text (say, using an AI generator to help write or edit a blog post that is partially human-written).
This type of partial detection (known as span classification or token classification) is a harder problem to solve and has less attention given to it in open literature. Current AI detection models do not handle this setting well.
They’re vulnerable to humanizing tools
Humanizing tools work by disrupting patterns that AI detectors look for. LLMs, in general, write fluently and politely. If you intentionally add typos, grammatical errors, or even hateful content to generated text, you can usually reduce the accuracy of AI detectors.
These examples are simple “adversarial manipulations” designed to break AI detectors, and they’re usually obvious even to the human eye. But sophisticated humanizers can go further, using another LLM that is finetuned specifically in a loop with a known AI detector. Their goal is to maintain high-quality text output while disrupting the predictions of the detector.
These can make AI-generated text harder to detect, as long as the humanizing tool has access to detectors that it wants to break (in order to train specifically to defeat them). Humanizers may fail spectacularly against new, unknown detectors.
Test this out for yourself with our simple (and free) AI text humanizer.
Similar Posts
Are AI Mode and AI Overviews Just Different Versions of the Same Answer? (730K Responses Studied)
Google’s AI Mode generates responses that are 4x longer than AI Overviews (on average). When we first noticed this, the natural assumption was that AI Mode simply expands on the same information, taking AI Overview’s concise answer and adding more detail from the same sources. But after analyzing 730,000 response pairs, we found something unexpected:…
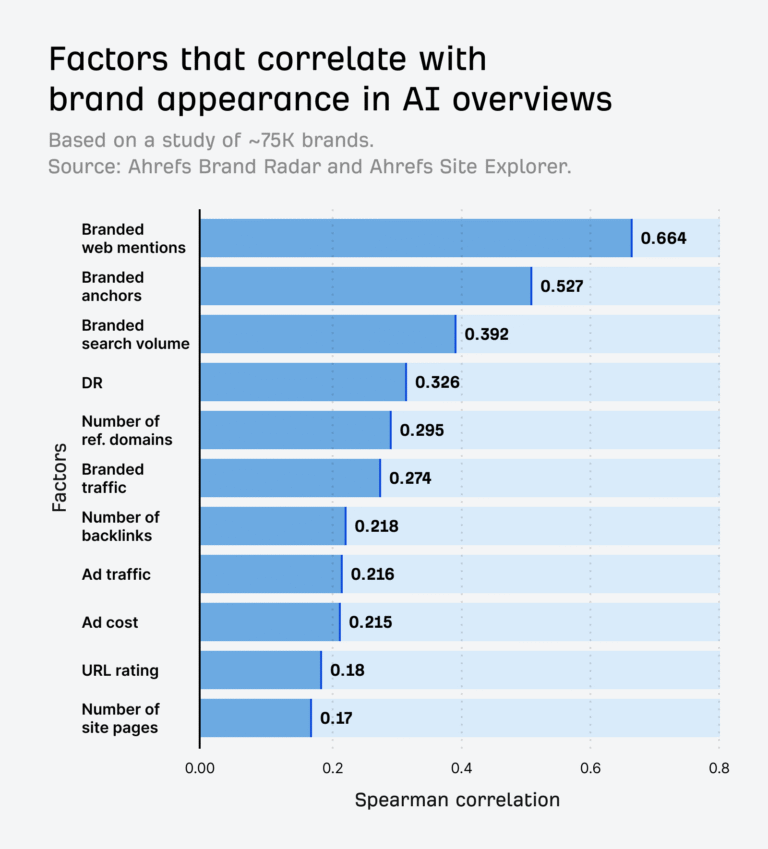
An Analysis of AI Overview Brand Visibility Factors (75K Brands Studied)
With Google’s AI mode developments, we’re heading toward a future where search results could eventually roll up into one big AI Overview. Soon it won’t be a case of “Should I, or shouldn’t I optimize for AI Overviews?” If you want any chance of search visibility, you’ll need to understand how to rank in Google’s…
How to Use Gmail with a Custom Domain: An Easy Step-By-Step Guide to Setup for Newbies
Need to know how to use Gmail with a custom domain? Be prepared to discover everything you need, plus a shiny new alternative maybe. Step this way… Why would you want to use Gmail with a custom domain? Well, every business wants to really connect with its customers. If you’re anything like the majority of…
16 Top Search Engines in 2025 (Including Google Alternatives)
What are the top search engines in the world? It depends on what you’re looking for. Slowly disappearing are the days when just one search engine dominates over the rest. The Internet is fragmenting, and people may choose a search engine over others because of specific use cases. So, here are the top search engines, classified…
GEO, LLMO, AEO… It’s All Just SEO
As a marketer, I want to know if there are specific things I should do to improve our LLM visibility that I am not currently doing as part of my routine marketing and SEO efforts. So far, it doesn’t seem like it. There seems to be massive overlap in SEO and GEO, such that it doesn’t…
The 50 Fastest-Growing Companies (January 2025)
We’ve analyzed 2,500 startups to identify the fastest-growing companies in search over the last year. 2024 was an especially challenging year for startups. Investors exerted extra caution in the face of inflation and rising interest rates, leading to a 26% decline in funding compared to 2023. But it wasn’t all doom and gloom. Sectors like AI and…