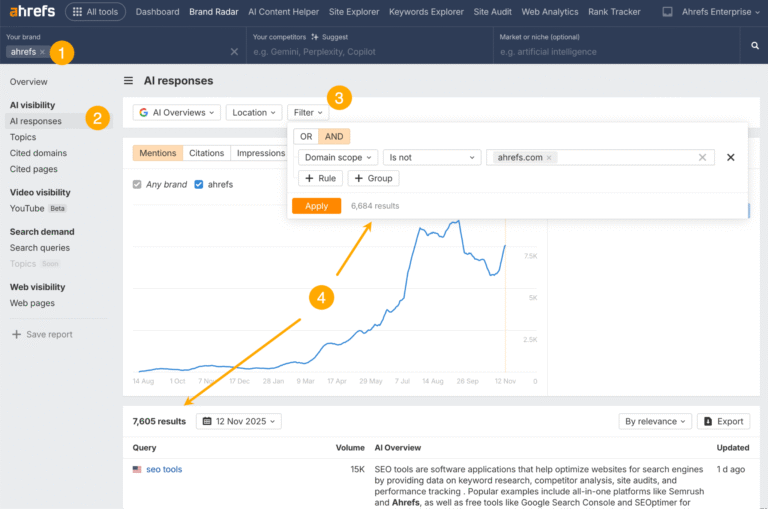
Developers and marketers are being told to add llms.txt files to their sites to help large language models (LLMs) “understand” their content.
But what exactly is llms.txt, who’s using it, and—more importantly—should you care?
In a nutshell, it’s a text file designed to tell LLMs where to find the good stuff: API documentation, return policies, product taxonomies, and other context-rich resources. The goal is to remove ambiguity by giving language models a curated map of high-value content, so they don’t have to guess what matters.
A screenshot from the proposed standard over on https://llmstxt.org/.
In theory, this sounds like a good idea. We already use files like robots.txt and sitemap.xml to help search engines understand what’s on a site and where to look. Why not apply the same logic to LLMs?
But importantly, no major LLM provider currently supports llms.txt. Not OpenAI. Not Anthropic. Not Google.
As I said in the intro, llms.txt is a proposed standard. I could also propose a standard (let’s call it please-send-me-traffic-robot-overlords.txt), but unless the major LLM providers agree to use it, it’s pretty meaningless.
That’s where we’re at with llms.txt: it’s a speculative idea with no official adoption.
Don’t sleep on robots.txt
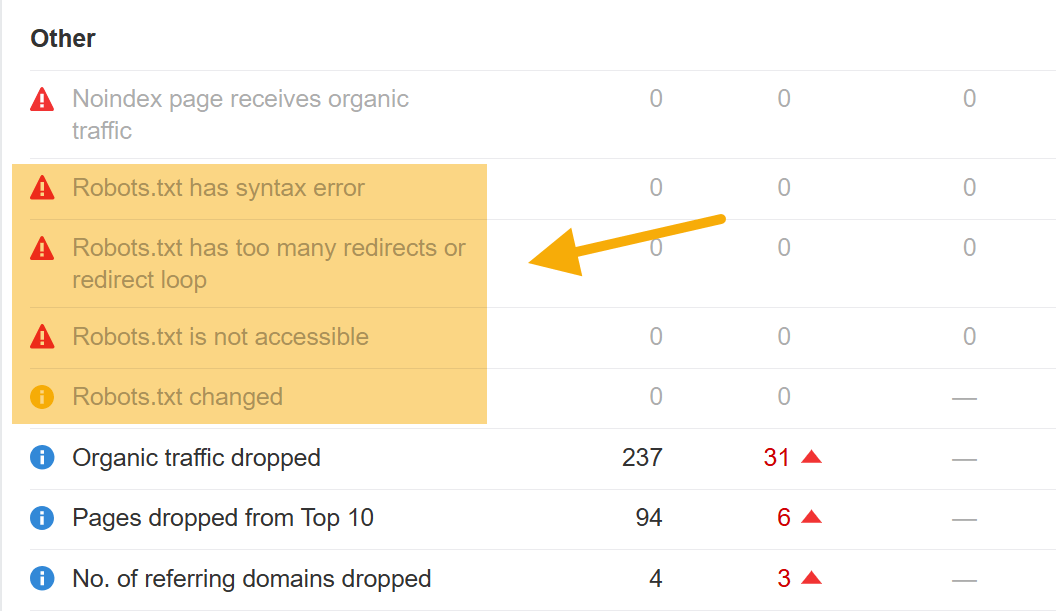
llms.txt might not impact your visibility online, but robots.txt definitely does.
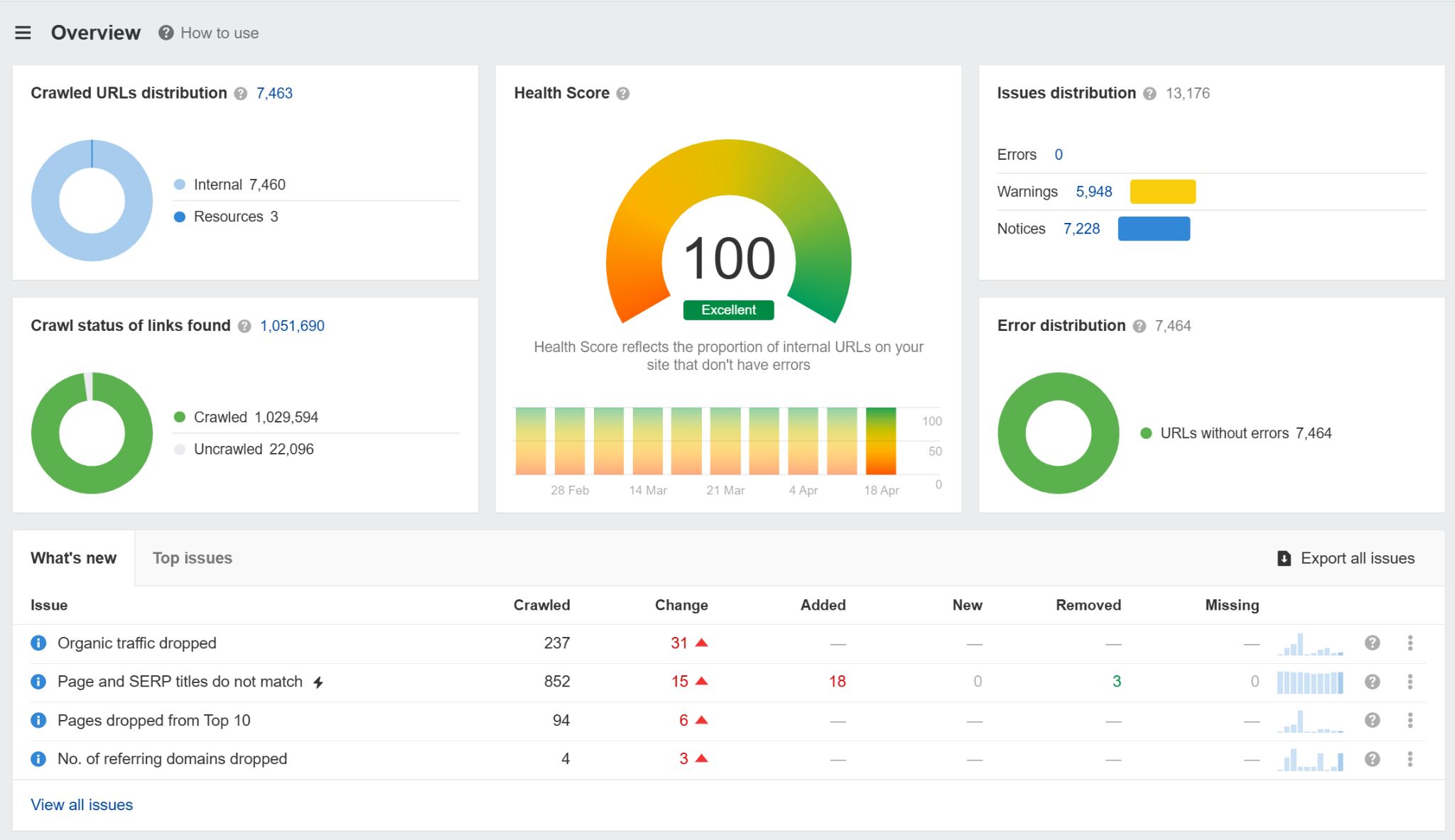
You can use Ahrefs’ Site Audit to monitor hundreds of common technical SEO issues, including problems with your robots.txt file that might seriously hamper your visibility (or even stop your site from being crawled).
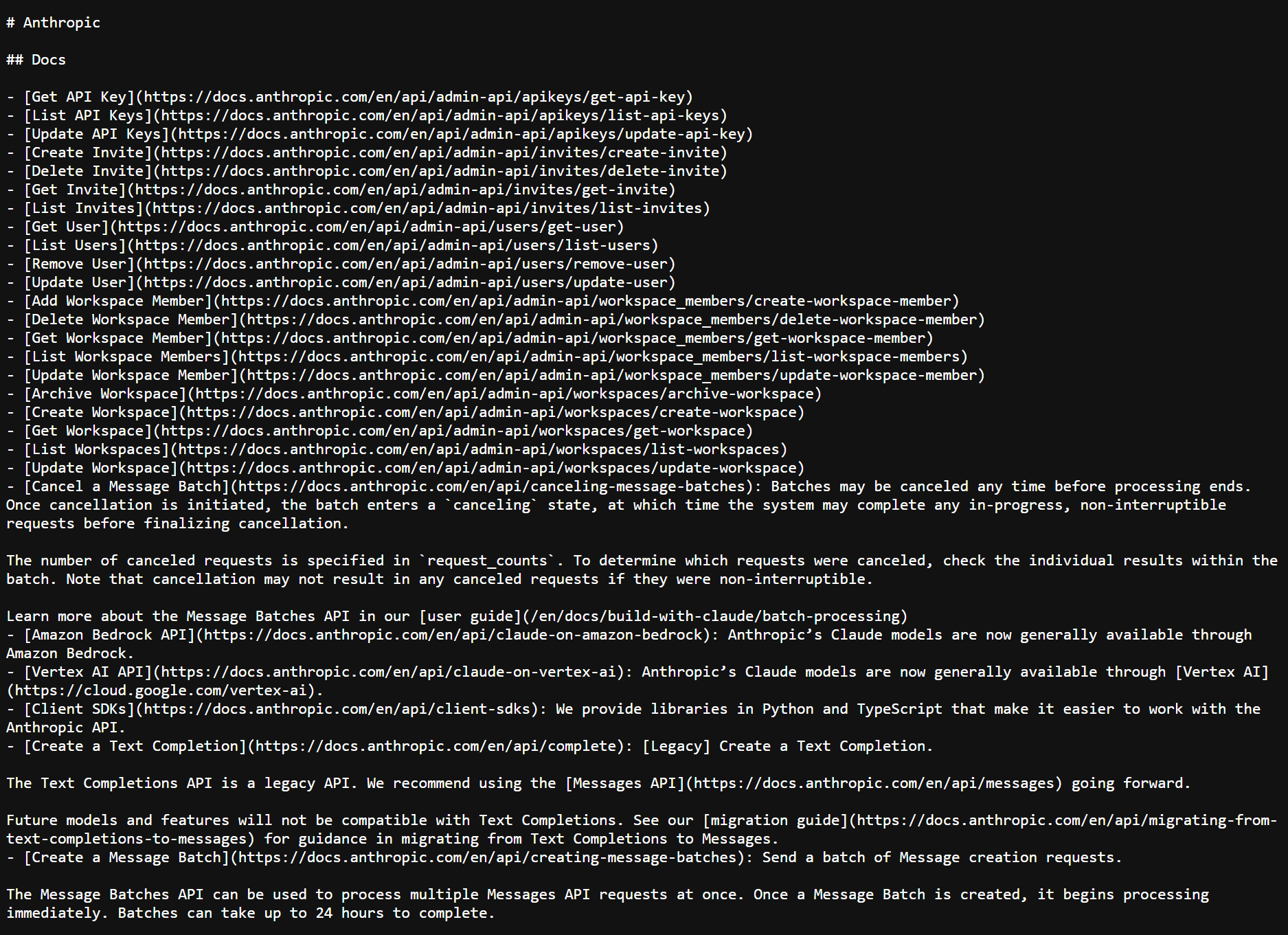
At its core, llms.txt is a Markdown document (a kind of specially formatted text file). It uses H2 headers to organize links to key resources. Here’s a sample structure you could use:
# llms.txt ## Docs - /api.md A summary of API methods, authentication, rate limits, and example requests. - /quickstart.md A setup guide to help developers start using the platform quickly. ## Policies - /terms.md Legal terms outlining service usage. - /returns.md Information about return eligibility and processing. ## Products - /catalog.md A structured index of product categories, SKUs, and metadata. - /sizing-guide.md A reference guide for product sizing across categories.
You can make your own llms.txt in minutes:
- Start with a basic Markdown file.
- Use H2s to group resources by type.
- Link to structured, markdown-friendly content.
- Keep it updated.
- Host it at your root domain: https://yourdomain.com/llms.txt
You can create it yourself or use a free llms.txt generator (like this one) to make it for you.
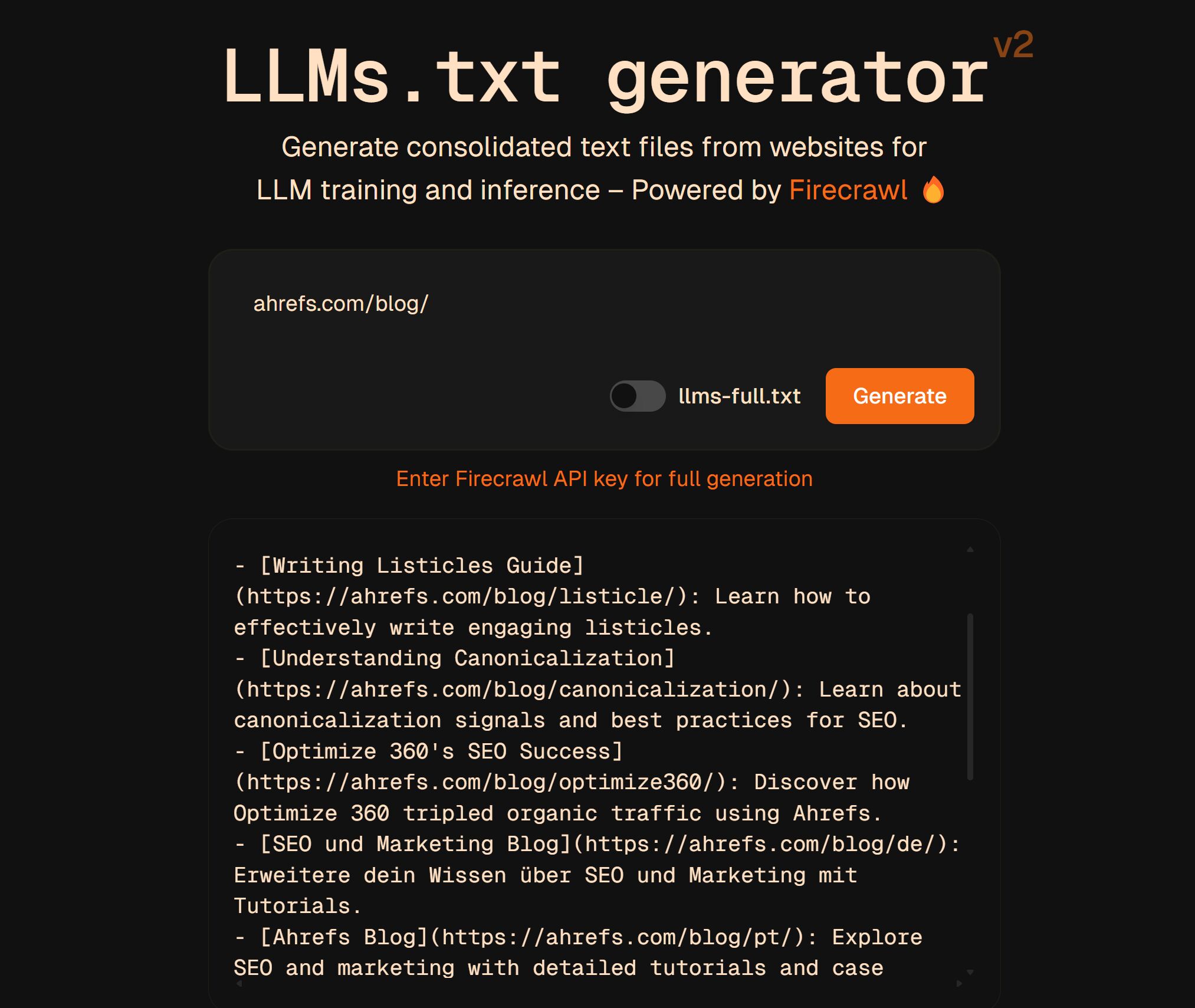
I’ve read about some developers also experimenting with LLM-specific metadata in their llms.txt files, like token budgets or preferred file formats (but there’s no evidence that this is respected by crawlers or LLM models).
Here are a few examples:
- Mintlify: Developer documentation platform.
- Tinybird: Real-time data APIs.
- Cloudflare: Lists performance and security docs.
- Anthropic: Publishes a full Markdown map of its API docs.
But what about the big players?
So far, no major LLM provider has formally adopted llms.txt as part of their crawler protocol:
- OpenAI (GPTBot): Honors robots.txt but doesn’t officially use llms.txt.
- Anthropic (Claude): Publishes its own llms.txt, but doesn’t state that its crawlers use the standard.
- Google (Gemini/Bard): Uses robots.txt (via User-agent: Google-Extended) to manage AI crawl behavior, with no mention of llms.txt support.
- Meta (LLaMA): No public crawler or guidance, and no indication of llms.txt usage.
This highlights an important point: creating an llms.txt is not the same as enforcing it in crawler behavior. Right now, most LLM vendors treat llms.txt as an interesting idea, and not something that they’ve agreed to prioritize and follow.
But in my personal view, llms.txt is a solution in search of a problem. Search engines already crawl and understand your content using existing standards like robots.txt and sitemap.xml. LLMs use much of the same infrastructure.
As Google’s John Mueller put it in a Reddit post recently:
AFAIK none of the AI services have said they’re using LLMs.TXT (and you can tell when you look at your server logs that they don’t even check for it). To me, it’s comparable to the keywords meta tag – this is what a site-owner claims their site is about … (Is the site really like that? well, you can check it. At that point, why not just check the site directly?)

Disagree with me, or want to share an example to the contrary? Message me on LinkedIn or X.
Further reading
Similar Posts
Do AI Assistants Link When Mentioning Brands? For Ahrefs, Only 28% of the Time
AI assistants mention brands constantly but they rarely include links. When I tracked brand mentions for Ahrefs across six AI platforms, I found they linked to Ahrefs as rarely as 10% of the time for AI Overviews, and as often as 50% of the time for Perplexity. But here’s what matters more: in our case,…
UX and SEO: A Guide for Winning the Searcher, Not Just the SERP
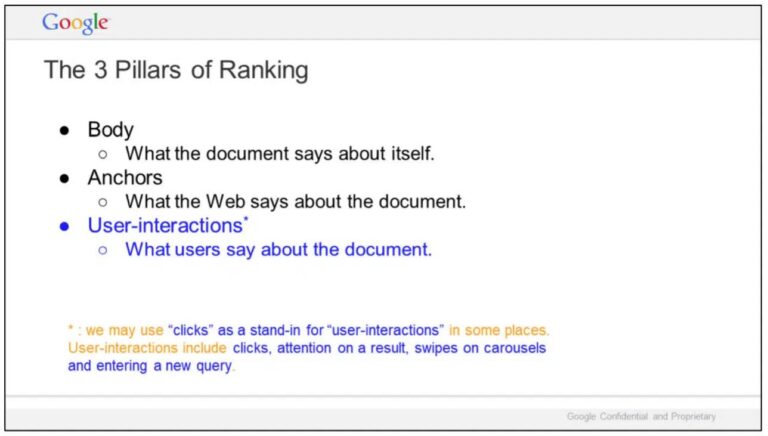
UX and SEO are interconnected in more ways than many people realize. User interactions, also called UX signals or user signals, include things like clicks, scrolls, swipes, and mouse hovers. These now play a major role in how Google ranks content and which brands gain more visibility in search results. Here’s everything you need to…
What is Domain Privacy Protection & Do I Need It? A Guide to Protecting Information
In this article, we explore what domain privacy protection is and why it matters. You’re busy securing your domain. It’s the name you’ve always wanted, so you’re super excited. Then, you notice the option to add domain privacy protection. Wait… say what, now? Domain privacy protection? Well, domain privacy protection is just what it says…
.org vs .com: What’s the Difference & How to Choose Which Domain Extension Is For You
.com and .org are both well-known examples of domain extensions. But what is .com exactly, and what is .org? And does it matter which one you use? (Spoiler alert: yes.) When you set up a website for a business or a non-profit organisation, you might think the most important part of the address is the…
Event Promotion: 10 Tactics We Used to Sell Out a 500-Person Conference
Last year, we ran Ahrefs Evolve: a sold-out, 2-day, 500-person conference at Pan Pacific Orchard in Singapore. I interviewed Shermin Lim, our events marketer, to find out how we marketed the conference and sold out all our tickets. Here’s everything we did to promote the conference. You can use these same strategies (or be inspired…